序
公司的应用服务通过kubernetes集群部署的,集群包含5个节点。最近其中一节点占用一直维持95%,遂进行问题排查。
问题排查
容器的问题?
首先先把该机器设置为”不可调度”(防止后续操作死灰复燃),然后将部分内存占用高的调度到其他机器上(如nginx-ingress)
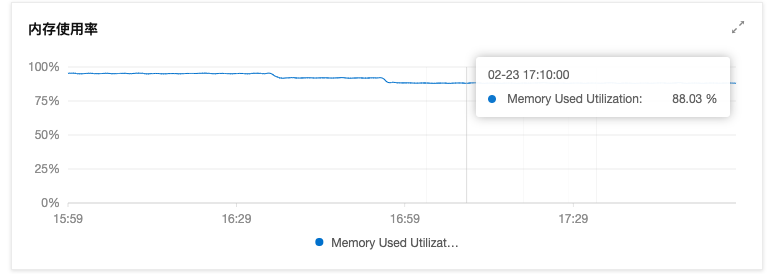
内存确实降下来了(一点点😅),起码先不用频繁触发报警
kubernetes的问题?
因为节点是购买自阿里云的ECS,且这些节点无法远程登录,排查工作一度暂停。后来换用了Lens对集群进行管理后发现可以轻松登录节点进行操作了。

进入shell之后执行top命令然后按大写M查看内存占用最高的服务,看到了rsyslogd(当时忘了截图了)
Google了一番后得知rsyslog是日志收集服务,主要是通过以下文件收集
| 路径 | 描述 |
|---|---|
| /var/log/messages | 服务信息日志(记录linux操作系统常见的服务信息和错误信息) |
| /var/log/secure | 系统的登陆日志(记录用户和工作组的变化情况,是系统安全日志,用户的认证登陆情况 |
| /var/log/maillog | 邮件日志 |
| /var/log/cron | 定时任务 |
| /var/log/boot.log | 系统启动日志 |
然后tail -f /var/log/messages一下,好家伙,日志一直刷刷刷的跑
1 | kubelet_volumes.go:128] Orphaned pod "***" found, but volume paths are still present on disk. : There were a total of 1 errors similar to this. Turn up verbosity to see them. |
(大致恢复了事故现场,截图丢了)
再Google一番后里面这里有两个问题待解决
僵尸Pod
出现Orphaned pod "***" found就是僵尸Pod的问题了,一般是因为删除容器的时候没删干净,导致配置文件残留在节点机器上,k8s就会不断尝试给它复活但是基本上会复活失败
进入/var/lib/kubelet/***,然后cat etc-host看一下该容器的名字,然后去kubectl get pods | grep (容器名字)看是否还在(一般都是不在的了)
然后对文件夹进行删除(如有mount volume之类的要先unmount,我这里没有mount所以可以直接删掉)
好了,现在看日志就没有kubelet_volumes.go的报错了
内置container组件问题
看这里的描述k8s 问题处理似乎是container版本过旧或者不兼容,按他的说法去更新一下就好了
1 | rpm -Uvh https://download.docker.com/linux/centos/7/x86_64/edge/Packages/containerd.io-1.2.10-3.2.el7.x86_64.rpm |
如果是用Lens去登录节点的话更新过程会断开连接,不要慌,过一会而就能重连了。
执下手尾
处理完后看看tail -f /var/log/messages,此时没有疯狂刷日志了,但rsyslogd的内存占用还没下来,遂进行网管必备的重启大法
1 | systemd restart rsyslog.service |
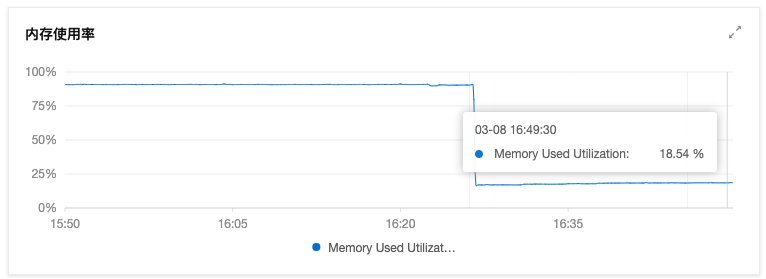
此时再看top,内存占用最高的不是它了
再去阿里云的监控看看,内存占用暴跌至正常水平😄
鸣谢
rsyslogd、systemd-journald内存占用高解决方案
挂载失败-日志中显示僵尸pod的问题
k8s关于Orphaned pod found - but volume paths are still present on disk的处理
k8s 问题处理